转载自:Windows7上安装pytorch1.11后报api-ms-win-core-path-l1-1-0.dll错误的解决方法
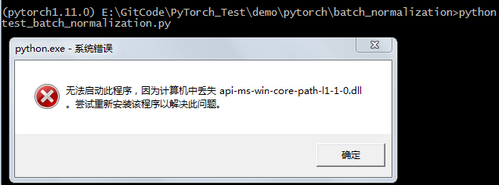
在Windows7上通过Anaconda安装PyTorch v1.11.0后,执行程序时报如下图所示错误:无法启动此程序,因为计算机中丢失api-ms-win-core-path-l1-1-0.dll。尝试重新安装该程序以解决此问题。
此Windows7上,之前已安装过PyTorch的v1.8.1,可正常执行程序。
搜索后发现Windows7本身确实没有api-ms-win-core-path-l1-1-0.dll这个库。从https://cn.dll-files.com/api-ms-win-core-path-l1-1-0.dll.html 下载此库,Verison为6.3.9600.16384,最新版本。
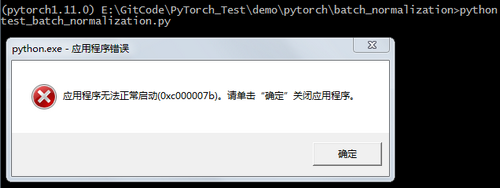
将此库放到C:\WINDOWS\System32目录下或D:\ProgramFiles\Anaconda3\envs\pytorch1.11.0目录下,错误会变成:应用程序无法正常启动(0xc000007b)。请单击”确定”关闭应用程序。如下图所示:出现“0xc000007b”错误,说明我们刚下载的是32位的dll,但是我们是64位的程序,因此也需要64位的dll。微软官方只提供了32位的dll。
在PyTorch v1.8.1中依赖Python的版本是3.7.11;在PyTorch v1.11.0中依赖的Python的版本是3.10.4。
根本原因是Python 3.9及以上版本已不适用于Windows7。workaround的解决方法如下:
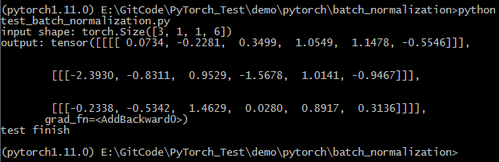
从https://github.com/nalexandru/api-ms-win-core-path-HACK/releases 下载最新版本0.3.1,即api-ms-win-core-path-blender-0.3.1.zip,解压缩,将x64目录下的api-ms-win-core-path-l1-1-0.dll拷贝到D:\ProgramFiles\Anaconda3\envs\pytorch1.11.0目录下,再次执行以上程序显示正常,如下图所示:
GitHub: https://github.com/fengbingchun/PyTorch_Test
相关文章: